Overview
Event distribution involves taking a single input event and copying it to produce multiple output events. The critical point to understand about distribution is that it does not involve copying of data, distribution only copies events. This is significant for two reasons:
- Copying data is computationally expensive but copying events (i.e. references to data) is not
- Care must be taken when distributing events that reference data to ensure that consumers do not attempt to update the same data simultaneously
How does CLIP support distribution?

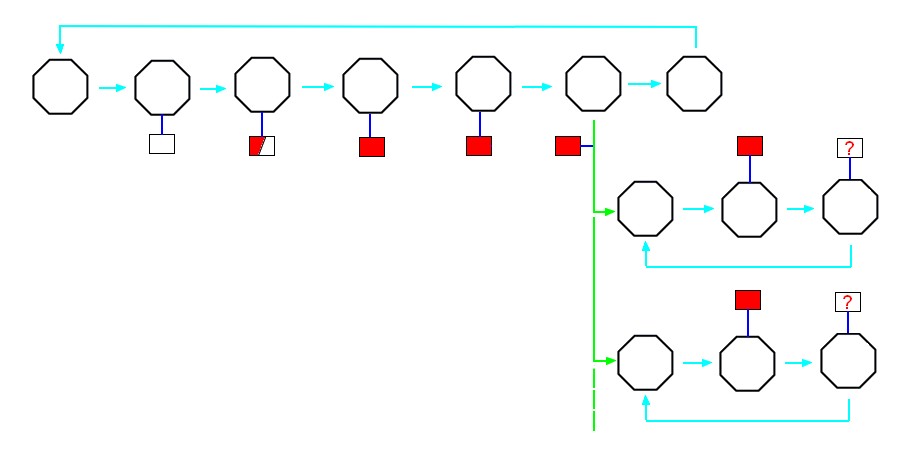
CLIP provides a Distributor object that implements event distribution. The following example shows a single 'ready-for-read' event produced by a transient store being distributed to three consuming methods. These methods will all see a copy of the same event, which contains a pointer to the memory location at which the store buffer is located:
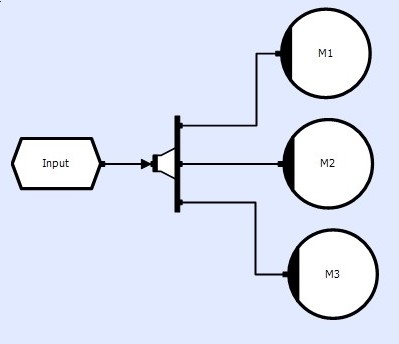
They can all simultaneously access the store and read its contents safely.
However, if either method intends to update the buffer, the two methods must be excluded from running simultaneously using additional circuitry (see Exclusion).
Why do we need an alternative to stack to manage data lifetime?
In a purely sequential environment, data-lifetime is not a problem. When entering a function, memory is allocated on the stack for local variables and when returning, the memory is deallocated. In a multi-core or distributed environment however, the stack no longer works. This is because thread A might signal thread B and pass it a pointer to some local data that it has on the stack but that now means that thread A can't return from its current function because it would destroy the data and it doesn't know when thread B is finished with it.
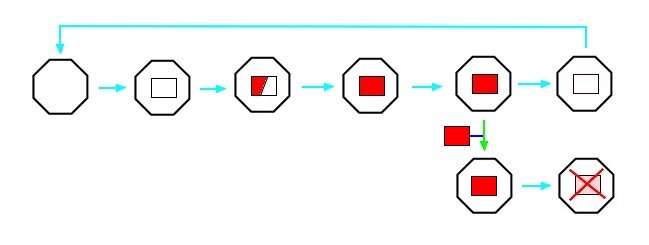
Alternatively, thread A could allocate data on the heap and signal thread B. Thread A can now safely return and thread B can dispose of the data when it is done
but what if the data is distributed to thread C and thread D also? Who takes responsibility for clearing up the data when everybody is finished?
The simple solution to this problem is to make a copy of the data for each thread and they can each dispose of their own but as we said above, copying data is computationally expensive and so the application will pay a severe performance penalty for adopting this strategy.
It is clear that an alternative to the stack is required that works in a concurrent environment and distribution provides this alternative.
How does distribution provide this?
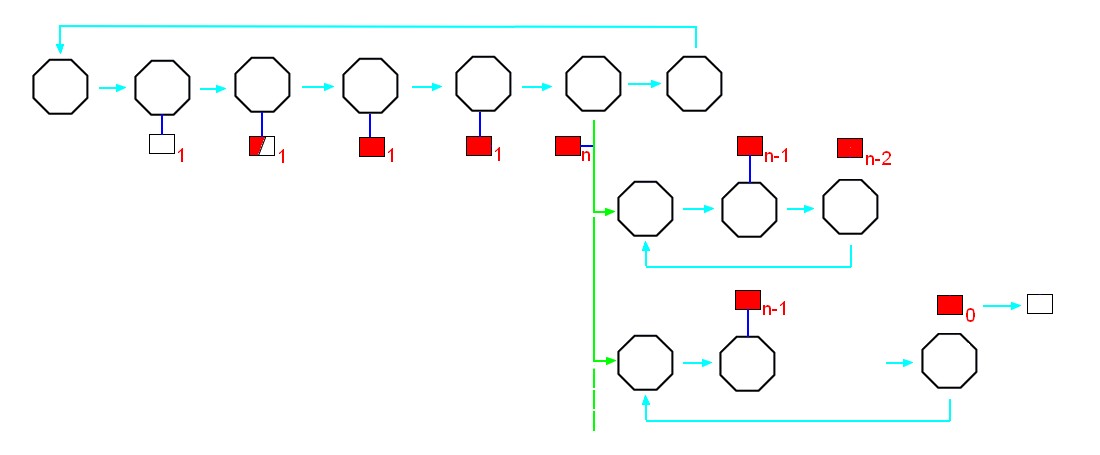
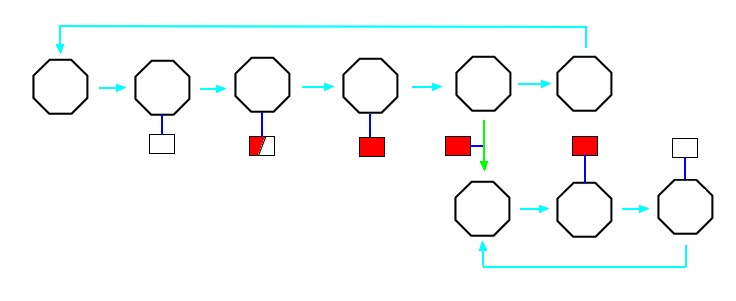
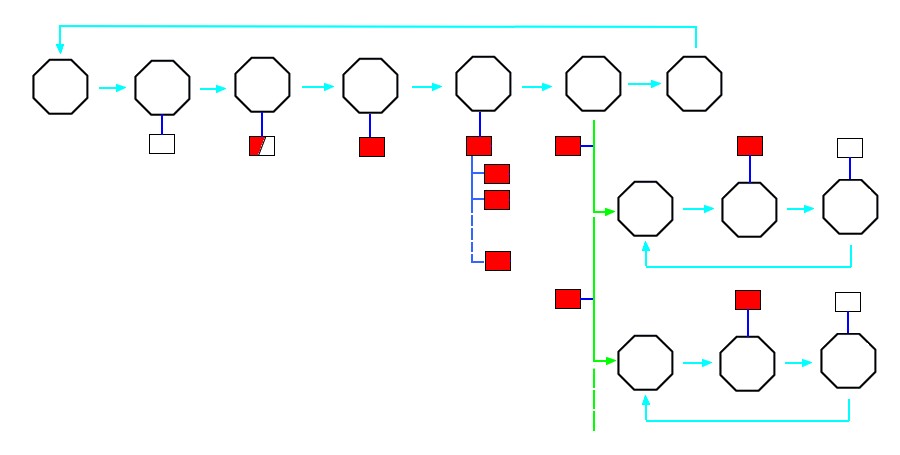
Each consumer from a distributor both requests and closes the distributed event so the distributor knows when everybody is complete and can close the original event thereby destroying the data. This is a similar notion to managed memory in which a smart pointer holds a reference count and deletes the data when the count reaches zero.
The following diagram illustrates the event sequence when multiple consumers request a distributed event.